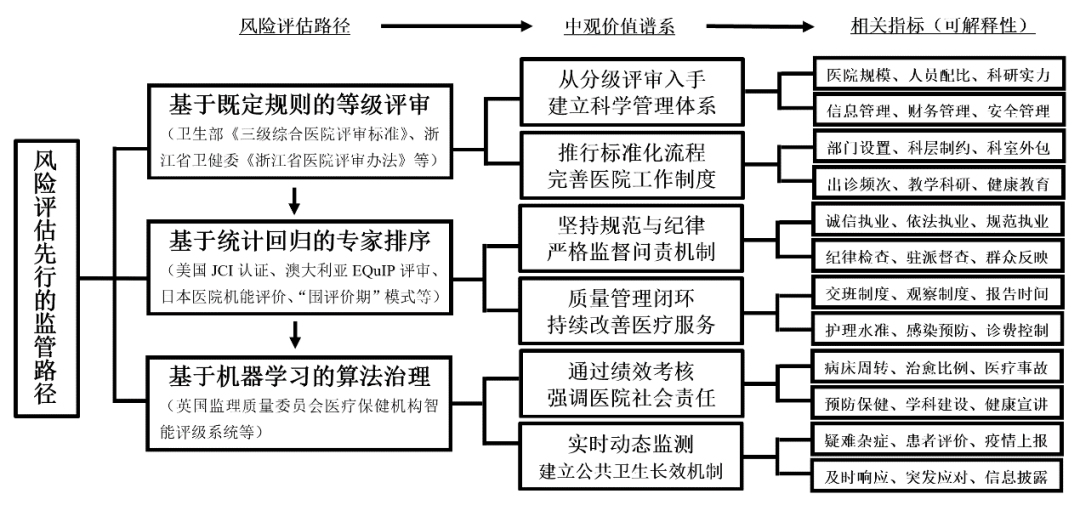
点击蓝字 关注我们 公共卫生领域算法治理的实现途径 及法律保障 作者简介:唐林垚,中国社会科学院法学研究所助理研究员。 文章来源:原文发表于《法学评论》2021年第3期,感谢作者授权推送。 内容摘要:政府向第三方机构下放评审权,标志着医院分级管理工作从基于既定规则的等级评审向基于统计回归的专家排序转变,但单纯的患者声誉参考显然无助于重大公共卫生事件中风险评估先行的监管实践。数字抗疫的稳步推进,或将疫情防控常态化时人们对算法治理的主观想象变为现实,其合法性取决于“升格推演”的指标求解方式能在多大程度上缓解监管资源稀缺并避免道德危机。可解释性的法律要求、规范续造的边界限制,框定了机器学习模型“生成式”构架的仿生路径以及由排序算法向聚类和分类算法递变的必然趋势。公共卫生领域算法治理的实现,还需以消除行业数据共享限制的宏观政策、消解编译偏差的中观价值谱系、消弭算法歧视的微观条例规章作为法律保障。 关键词:算法治理 人工智能 分级评审 风险评估 法律保障 问题与方法 监管部门长期以来面临的主要矛盾,是日益增长的监管对象和监管资源不平衡不充分之间的矛盾;公共卫生领域尤其如此。截至2020年10月底,我国共有医院3.5万个,医院之外的医疗卫生机构,更是多达102.6万个。与上百万家机构及动辄数千万名从业人员形成鲜明对比的是,行使监管权的中央和地方卫生健康委员会(以下简称卫健委)、疾病预防控制中心和医疗保障局等,虽在长期摸索中逐渐形成了“国家主导、地方联动”的动态监管体系,但这些一线监管机构无论是在人力配比还是在资源储备方面,均难随行业的爆发式增长水涨船高,使得“心有余而力不足”的监管困局一直存在。由于合规成本乃人力成本之外的头号开销,部分医疗保健机构监管套利之心尤甚。于是乎,但凡有监管部门力所不逮之处,定然行业乱象丛生,医患关系持续恶化,法律底线节节败退。在经济发展趋缓的大形势下,监管部门合理开源的渠道渐次萎缩,自身禀赋不足以支撑宏伟抱负的情形愈发严重。既然不能无节制地扩充编制和规模,监管部门只能竭尽所能,将有限的资源利用到极致。伴随着新公共治理理论的崛起,风险评估先行的监管路径应运而生:监管部门一改过去“出现问题——解决问题——因解决问题造成新问题”的被动路径依赖,通过“减轻或豁免对低风险对象的监管,将更多的资源和注意力用于对高风险对象的监管”,在更有效遏制风险发生的同时却不额外加重监管部门和低风险对象的负担。 我国公共卫生领域风险评估先行监管路径的探索,始于改革开放初期,彼时我国医院按照行政区划、隶属关系、部门所有、条件分割体制设立和管理,长期存在机构布局不合理和资源分配不均衡等问题。为“打破由于基层薄弱,造成医疗系统结构不合理以致削弱整体功能的恶性循环”,卫生部于1989年发布《关于实施医院分级管理的通知》,启动了第一轮医院分级评审工作。《医疗机构管理条例》第41条规定:“国家实行医疗机构评审制度……对医疗机构的执业活动、医疗服务质量等进行综合评价……评审办法和评审标准由国务院卫生行政部门制定。”虽历经30年“上下求索”,评审标准、评审方式也屡经变革,医院分级评审工作至今未能实现风险评估先行的监管路径本应带来的提质增效,几乎完全沦为民间寻医问诊的声誉参考。 新冠疫情发生后,习近平总书记在统筹推进新型冠状病毒(以下简称新冠)肺炎疫情防控和经济社会发展工作部署会议上提出了“科学防治、精准施策”的工作要求,足见风险评估先行的监管路径在重大公共卫生突发事件中的应对意义。先前的医院分级评审结果未能助力政府“问题导向、目标导向和结果导向”的精准施策,也无助于苗头性和趋势性问题的化解,反倒是横空出世的健康码和各类居家隔离APP,在大数据和人工智能技术的加持下,有望根据个体风险特征和区域风险程度,协助有关部门计算与防控目标相称的监管投入。数字抗疫的稳步推进,给下一轮医院分级评审带来了方法论上的启示:以算法为核心的人工智能技术能否助推风险评估先行的监管路径?如果能,其取代传统评审方式的正当性依据何在?兼具授权性规则和义务性规则的双重意味,帕洛夫斯基将评审定义为“以比较式的类型构建取得法的认识”,那么,从法诠释学和类型构造的角度出发,公共卫生领域的算法治理应如何构建?公共卫生领域的科技进步,关乎民生、关乎产业发展、关乎国家安全和社会稳定,是国家治理体系和治理能力现代化的重要组成部分。技术普惠既需要宏观层面的产业政策作为支撑,也需要中观层面的法律法规确立价值导向,更需要微观层面的规范指引矫正实践偏误。在“支撑、引导和矫正”的语境下,本文着重探讨公共卫生领域算法治理不可或缺的法律保障,以期为智慧医疗、数字抗疫之实现明确途径。 医院评审制度的法律沿革与算法 治理的先行实践 凡对“卫生法律关系主体所实施的行为进行道德维度的评价或审查的依据,及其所构成的规则体系”,均属于卫生法下的伦理范畴。从规则意义来看,伦理对卫生法影响深刻,且常因科技的发展不断生发出新伦理,又反过来推动卫生法的修改。在漫长的实践过程中,为实现风险评估先行的监管路径,公共管理部门大致演化出了三种对卫生法律关系主体进行评价或审查路径,由远及近分别为基于既定规则的等级评审、基于统计回归的专家排序以及基于机器学习的算法治理。 (一)基于既定规则的等级评审 基于既定规则的等级评审,盛行于上世纪60年代美国各州公共卫生署对本州餐馆的卫生安全评级。监察员依照既定的评审标准对餐馆进行周期性检查,各餐馆也依照公共卫生署制定的食品卫生标准改善自身的营业环境,评审结果以A(高信誉度低风险)、B(中等信誉度一般风险)、C(低信誉度高风险)和D(强制取缔)公示于餐馆门口,直接影响市民的就餐意愿。公共卫生署根据受评餐馆的风险级别,确定下一轮卫生检查的间隔周期,在降低自身监管成本的同时也减少了高信誉低风险餐馆的合规成本。 公共卫生署的评审标准并非一成不变,而是随时根据监察员与受评餐馆的反馈进行修改和完善,积年累月的规则变迁充分反映了公共卫生署与受评餐馆博弈背后的“参与者多数同意”,成为等级评审所依赖的具体规则的合法性根源。然而,这种基于既定规则的等级评审方式过于简单,存在诸多问题。其一,评审标准由监管部门根据先验知识而非普查或调研结果设计,部分规则不可避免地建立在有缺陷的假设之上。其二,历次评审标准的改进,虽广泛听取了被监管者的意见,但在“资本多数决”之下,最终形成的标准,只能反映“最主流”被监管者的意志,致使部分被监管对象在规则的演进过程中不断被边缘化。这些问题在卫生安全评级上的直接体现为规则对特定餐馆的优待或歧视:因高度流程化,大型连锁快餐店的卫生评级甚至高于高档餐馆;因原料和烹饪方式不同于主流西餐,中餐馆难以获得较高评级。 我国早期的医院分级评审,即采取了基于既定规则的等级评审方式。依据1989年《医院分级管理办法(试行草案)》,全国范围内的医院将按照不同功能和任务统一划分为“一、二、三”三级,分别对应面向一定人口社区的基层卫生院、面向多个社区的综合医疗卫生服务机构和面向多个地区的高水平综合医院,由省级委员会评审。每级别再根据分级管理标准划分为“甲、乙、丙”三等,由地(市)级委员会评审;三级医院增设特等级别,由部级委员会评审。如果说,“一、二、三级别划分”还算有明确的医院规模作为参照标准,那么,“甲、乙、丙等级确立”则在国务院授权卫生部制定的指导文件中找不到任何依据。地(市)级委员会在评审中要么想当然地随意制定标准,要么再次机械重复以医院规模为唯一考察依据的既定标准,致使以“成分论英雄”的歧视现象屡见不鲜:大型精神病院或妇幼保健医院多被划分至丙等、县级以下医院基本同甲等无缘。 1998年8月,卫生部发布《关于医院评审工作的通知》,紧急叫停全国医院分级管理与评审工作。在此后长达13年的调整期内,卫生部先后开展了“医院管理年”“质量万里行”等小型评审活动,动态探寻更加规范和科学的医院评审标准。2011年,卫生部遵循国际PDCA循环原理,重新制定了《三级综合医院评审标准》,开始了第二轮全国医院分级评审工作。虽然同样采取基于既定规则的等级评审进路,新一轮的评审标准较之前有了长足的进步——总计391条标准与监测指标,以医院公益性(32条)、医院服务(35条)、患者安全(27条)、医疗质量安全管理(167条)、护理质量持续改进(31条)和医院管理(62条)为重点考察对象,兼顾37条专门对医院进行风险监测和追踪评价的日常统计学评价指标。在其他方法阙如的背景下,新一轮分级评审极大地促进了医疗保健机构的合理定位与分级发展,但其弊病也显而易见:标准越明确,就越容易被破解。据不完全统计,在第二轮医院分级评审工作开展不到一年半的时间内,共有240家地方医院从二级晋升为三级,并且多数直接晋升为甲等医院。面对接踵而至的“升级”势头,2012年6月,卫生部发布《关于规范医院评审工作的通知》,一举推翻了此前的分级结论,并对获得二级及以上医院展开复核评审工作。 一直以来,《三级综合医院评审标准实施细则》要求评审委员会秉承“不降低标准,保证质量安全”的原则从严评审,工作量大、任务繁重,监管部门和受评医院可谓双双不堪重负,风险评估先行的监管路径更是无从谈起:如果前一轮分级评审已经客观、准确地对全国医院的质量和风险进行了有效评估,那么推倒重来的新一轮评审工作自然毫无必要——监管部门只需重点关注此前评审结果不佳的医院即可,在给低风险医院喘息空间的同时,也减少自身的监管负担。 (二)基于统计回归的专家排序 2017年9月,国务院印发了《关于取消一批行政许可事项的决定》(以下简称《决定》),取消了国家卫计委对各省、市、自治区三级综合医院评审结果的复核与评价权,并要求各级评审委员会真正做到“去行政化”;《决定》还进一步要求监管部门要尽快实现从评审主体向监督主体的法律关系转换,将规则制定和维护的“裁判员”角色让渡给第三方。评审权下放是出于同国际接轨的综合考虑:目前,世界主流的医院评审体系多采纳了基于统计回归的专家排序路径,部分由政府监管部门主导,部分由第三方机构进行。 回顾我国此前医院分级评审制度的演进历程,在管办不分的医疗保健服务供给体制下,自上而下的规则设计存在指标不合理、过程不透明、结果不公平等问题。基于统计回归的专家排序,则试图以“更合理的指标”和“更透明的专家决策”,来达至“更公平的结果”,其理论渊源可以追溯至唐娜贝蒂安于1966年提出的三维质量评价理论,认为医疗保健服务中结构、过程和结果三者之间呈线性关系——健全的结构可以改良过程,而良好的过程能够促进良好的结果。在唐氏理论的指导下,各发达国家根据自身公共卫生领域现状,创造出了不尽相同的基于统计回归的专家排序方法,有些还成为了国际规范。例如,将质量管理和持续绩效提升贯穿始终的美国JCI认证、完全依赖测评工具和可比性资料的澳大利亚EQuIP评审、重视现场勘查和专家解读的日本医院机能评价等。 基于统计回归的专家排序的实践摸索,早于国务院发文之前。2008年,海南省医院评鉴暨医疗质量监管中心在全国率先实践“独立第三方”外部评审和风险监管的创新机制,以“围评价期”理论作为指导,融合了追踪方法学(TM)、根本原因分析(RCA)、品质管理圈(QCC)和平衡计分卡(BSC)等多重品质管理工具,构建了前期、中期和后期“耦合、联动、持续、循环”的长效医院评审模式,并在全国范围内推广。2016年,卫计委颁布《医疗质量管理办法》,以行政法规的方式鼓励采取全面质量管理(TQC)和疾病诊断相关组绩效评价(DRGs)等统计回归方式促进医疗质量的持续改进。与狂热追捧统计回归方式并行不悖的是,第三方评审机构空前强调“专家排序”的重要性。 从唐氏三维质量评价理论来看,基于统计回归的专家排序明显优于基于既定规则的等级评审,因为后者的各类风险指标过度集中于结果层面,缺少对结构和过程两大维度的评价。多维度统计回归工具的使用和跟踪长效机制的引入,在一定程度上促进了“以评促建、以评促改、评建并举”,但许多问题也由此产生。其一,在医院评审“去行政化”的大背景下,基于统计回归的专家排序得到监管部门默许甚至推崇,以至于各类统计方法和结果可以不经审查就直接公之于众,毫无程序正当可言,指标的可行性、有效性及稳定性经不起信度及效度检验。其二,虽然多重统计回归工具和品质管理工具得以充分应用,但几乎所有第三方机构,都存在调研能力不足的状况,无力使用失效模式与效应分析(FMEA)、负向标杆管理(N-BMK)等风控工具对医院安全隐患进行预测,使得医疗服务中结果和结构之间的线性关联链条被打断,唐氏理论良好适用的逻辑基础不复存在。其三,基于统计回归的专家排序产生了新的“过程不透明”问题。 针对专家排序的最有力质疑,聚焦于专家决策的一致性和准确性。之所以引入专家决策,是因为统计回归模型的各项指标难以吸收医疗领域的各类默会知识。例如,医生出诊率较高说明医院管理更好吗?未必,因为医生在出诊之外,还必须有充足的时间进行医学实验和学术研究,这些都是医生的本职工作。从诠释法学的视角来看,专家决策可以避免因数据误导造成的统计结果偏差,还能从资深业内人士角度使结果和数据的解释获得必要的弹性。即便如此,近20年的实证研究几乎一边倒地证明,无论是何种类型的评审或排序、无论对经验和隐性知识的需求有多高,专家决策都不能带来比普通统计预测模型更优的结果,在突发心脏病预防、精神病学和神经心理学诊断等方面班班可考。2020年,复旦大学医院管理研究所在医院排序时共向4173位专家发出挂号信,收到有效回执2657份,回复率为63%,比2010年44%的回复率有了显著提升,但是,这些分布在不同地区和不同临床专业的专家们,真的能够代表上亿名患者对全国范围内的医院给出具有可比性的评分吗?考虑到这些医院排行没有严格遵守古典德尔菲法要求的“多轮双向匿名反馈”的调查方法,答案显然是否定的。 (三)基于机器学习的算法治理 医院的分级评审的初衷,在于优化医疗资源配置:通过促进医院间的病理分流和多向转诊,让区域病疫风险“可防可控”。然而,无论是基于既定规则的等级评审,还是基于统计回归的专家排序,显然在效果上背离了上述初衷。医疗服务的效果具有不可逆的特征,关乎患者的“生死存亡”,在市场信息严重不对等的情况下,政府主导的分级评审结果和第三方机构给出的专家排序成为了广大病患唯一可以抓住的“救命稻草”,使得三甲医院门庭若市,基层医疗机构门可罗雀,排行榜之外的医院完全无人问津,只能通过购买搜索引擎关键字的方式获取流量。在新冠疫情爆发初期,大量疑似患者涌入武汉市中心医院或金银潭医院,造成了医院内部的聚集式“人传人”;社区卫生服务中心和小型诊所均可进行核酸检测及一般发热隔离,但直到大型医院无力继续接诊后,才逐渐发挥作用。 在指标选取方面,基于统计回归的专家排序和基于既定规则的等级评审相差无几,两种路径都充斥着大量仅凭直觉或约定俗成的先验指标:对医院的硬件规模和科研实力过于重视,却长期忽略患者的真实就医体验。在看清了评审的实质后,各地方医院为“争级上等”可谓不遗余力,投机性地通过增加医疗设备数量、引入正高职称人才的方式左右评审和排序结果,甚至将发表高影响因子的论文视为比救死扶伤更重要的工作。为了避免上述惯性延误抗击新冠肺炎的最佳时机,科技部2020年1月29日专门发文,要求各医疗单位及其科研人员“把论文‘写在祖国大地上’,把研究成果应用到疫情防控中,在疫情防控任务完成之前,不把精力放在论文发表上。” 综上所述,如果我国下一轮医院评审只是在形式上实现了从政府向第三方机构“放管服”、只是在方法论上完成了从基于既定规则的等级评审向基于统计回归的专家排序的转变,将无助于“推进卫生健康基本公共服务均等化、普惠化、便捷化和公共资源向基层延伸”,更不能在实质上提升监管部门应对“突发公共卫生事件”的能力。说到底,若评审不科学,则结果无意义——迄今为止的各种努力,最终都陷入了“形式主义”和“唯方法论”的伦理窘境。 近年来,大数据和人工智能等技术的发展,为公共治理领域的监管提供了独树一帜的解决方案。理论界和实务界的共同乐观并非痴人说梦。其一,大数据的“自然积累”或彻底颠覆统计学意义上的“数据搜集”。例如,用户只需授权联通、移动或电信集团查询疫情期间的行程数据,就能展示在过去30天内到达或途经过的敏感地区;返岗人员可以在网上自行填报,获取属于自己的二维健康码,作为特殊时期通行出入的电子凭证。在“数据多跑腿、群众少跑路”共识下,过去通行的“填表抗疫”等病理统计方法,被指责“官僚色彩严重”,已逐渐退出历史舞台。其二,机器学习技术的发展,促进了风险评估的“自动化”。透过合理的算法,机器学习模型可以从海量的大数据中识别出隐藏的模式、规律和倾向,并输出具有明确指向性的预测或评估。例如,将千万人的行程轨迹、载入机器学习模型,结合不同区域的确诊分布,就能粗略评估个体感染的风险概率。其三,卷积神经网络方法进一步提升了机器学习模型的层次和复杂程度,使得内建分层网络获取多层次特征信息成为可能,有望攻破过去需要人工确定指标的重要难题——相互叠加的算法可以根据不同维度的输入信息和各类变量自行探寻能够获得最合理输出的风险指标。外于语言、超乎实证,算法在诠释法学的意义上属于即便通过各种解释之间的冲突也难以获悉被解释的存在,其复杂性远超任何既定规则和统计回归方法,无法用普通人的逻辑和语言进行表达,自然,专家决策也就被排除在外。 算法治理的核心在于,从对规整对象既存状态的分级评审,转化为根据文本片段和规范数据进行的动态评价计算,目的是将主观与客观因素、偶然与必然结果之间的盖然性一览无余,促进监管部门的正面价值取向和技术规制的中立精神相互增益。与此同时,其思维本质从决定论向概率论的跳跃,将使算法治理内在的解释与商谈,从“利益主导话语权”的批判法学主张,向“各方互动合力”的、具有民主色彩的实验主义法学迈进。机器学习模型不会拘泥于主观价值判断,甚至不会受制于过往经验与事实造就的充满内在矛盾和主观间性的现有评价体系,而是在海量的大数据和文本中筛选出最能显示风险特征的维度或论题,对其进行逻辑嵌套与循环递归以寻求建立全新共识的种种可能性。这种评价的自创生实属破坏性创新,目的是要挣脱既定规则的相互掣肘,也或多或少具有彭加乐“约定主义”的特征,主张经验中出现的事实可以融会到无限不同假设构造中的任何一种。在公共卫生领域,英国医院分级评审率先步入算法治理的轨道:英国监理质量委员会从2013年开始着手建立智能评级系统,利用算法每4至6个月更新一次风险指标库。从能力范围来看,算法治理超越传统医院分级评审,不仅能借助“互联网+”重塑分级诊疗机制,还能同时促进国家医疗战略物资储备制度的构建和疫情防控预警预测机制的完善。 公共卫生领域风险评估方式的嬗变,印证了“以缺陷为代价的解决方案不能长久”的法伦理,在谨慎乐观的同时,我们不得不心生警惕,以公共目标为导向的算法治理是否存在边界?算法治理固然不可能完美无瑕,究竟遵循怎样的信息化程序,才能更好兑现公共卫生领域风险评估先行的监管承诺?进而言之,法律将如何影响算法?算法代码的字里行间又将如何体现法律? 公共卫生领域算法治理的规范性 分析及实现路径 本质上,风险指标的选取是一个关涉“规范内涵和事实结构”的法律命题,从未跳出“价值判断标准客观化”的篱藩。就像法官在寻求案件适用的法律规范时,需要通过准确无误的判断和联想找到适当的规范禀赋那般,我们期望机器学习模型在将大量规范、解释和事实都纳入运算范围之后,通过对数据和文本的交互参考来模拟自然人的理性判断,逐步筛选出(甚至创造出)可以被解释的规范所涵摄的各项指标。这正是算法治理的智能所在——它不依赖于既定的经验和知识,而是在机器学习过程中形成对底层数据的独特理解,它顺从又超越法律概念涵摄和类型归属进行拉伦茨所称的“一种为获得知识而进行的,有计划的活动”——法律续造。 (一)算法治理的正当性依据 一般而言,只要传统医院分级评审方式的指标选取具有显著缺陷,通过算法选择更优指标的行为就具有合理性,更何况,机器学习模型还能通过对大数据的挖掘识别一般人根本不会注意到的隐性规律和模式。诚然,基于统计回归的专家排序和基于既定规则的等级评审皆因指标的先验性饱受诟病,但这种诟病足以被视为对其规整范围内的特定事实缺乏适当规范的规则性漏洞吗?毕竟,从历次医院审查中沿袭下来的惯用指标,以及在世界范围内通行的支配性判定标准,都可被视为经过对话和论证程序的、经得起时间考验的共识,符合法哲学家所界定的“正义的标准”。问题的本源在于,机器通过学习所获得的“知识”是否一定优于自然人从过往经验和社会生活中获得的“知识”? 遍览现行所有公共卫生领域的风险评估指标,可以将其大致划分为三类:(1)投入类指标:例如,规模床位、设施设备、科研积累等;(2)服务类指标:例如,营养人员与床位比、技术操作规范、收费标准等;(3)结果类指标:例如,入院诊断与出院诊断符合率、无菌手术切口甲级愈合率、医院感染漏报率等。单从常识就能看出,投入类指标本身就可视为服务类指标的最佳预测性指标:规模更大、设施更齐全、科研实力更强的医院,必然能够提供更好的医疗服务。同理,投入类指标和服务类指标同时将对结果类指标产生重大影响:无论是什么疑难杂症,综合医院定然比社区卫生服务机构具有更高的抢救成功率,此间的逻辑关系,是更好的医院具有提供更好医疗服务的禀赋,而非医院因为提供了更好的服务从而被评审为级别更高的医院。算法治理优于自然人评价的可能之处,就在于能够跳出既有标准的重叠指涉,摆脱“感觉主义和先验的唯理主义强加的负担”,根据要“履行的操作以及由这些操作的结果对观念有效性的检验”,颠覆现有的评价体系。 在这个意义上,人们对算法治理抱有的普遍期待是,机器学习模型能够在海量大数据中“眼光往返流转”,不受既有规则的遮蔽、忽视重复细节对结果处理的现实意义,通过高频次的拟合甚至仿生尝试,求解出堪称圆满的整体性规则。这种续造规则的圆满性,以之前规则——即各项传统风险指标——已被证明的重叠指涉性为合法依据。然而,经验表明,在风险评估方面,并非全知全能的指标选择,才能得到符合法律规范的“正确”结果。甚至有学者指出,衡量质量的唯一有意义的方法是评估“收益”,即患者在医疗服务中获得的“价值”,这意味着将完全剔除投入类指标和结果类指标,唯“服务类指标”是举。即便可以证明,机器学习模型将更多的数据纳入其考量范围,在算法中也确实囊括了更多维度的风险指标,我们也无法因此得出算法相对于既定规则或专家排序具有更高规则圆满性的结论,因为,至少在适配性和可解释性方面,算法治理并没有明显的优势,甚至会因为可解释性的匮乏导致被撤销的法律效果。反对的观点指出,从波纳西茨中心度的方法来看,卷积神经网络不过是一种“指数级地将既定规则复杂化”的方式罢了。 在规则圆满性无法验证的情况下,基于机器学习的算法治理就只能从监管目的及监管效果中寻求正当性根源。从过往经验来看,无论是基于既定规则的等级评审,还是基于统计回归的专家排序,在结果上均不能清晰而准确地反映公共卫生领域的资源失衡状况和潜在风险指数,全然无助于风险评估先行的监管实践。本来旨在优化医疗资源配置的评审工作反而导致了医疗机构的盲目扩张和重复建设,本来有望促进监管部门进行分级管理的医院排序最终沦为了广大病患的声誉参考,其准确性和客观性还有待进一步考证。因此,只有在结果上成为监管部门风险评估先行监管路径的“最优解”,或至少成为相对于基于既定规则的等级评审和基于统计回归的专家排序的“更优解”,基于机器学习的算法治理才具有正当性。 (二)模型求解过程与规范续造边界 为了在公共卫生领域达成上述目标,基于机器学习的算法治理应当如何构建呢?纵观机器学习的历史,从上世纪80年代以仿生学为基础的感知机(Perceptron)到90年代完全基于数理逻辑的支持向量机(SupG portVectorMachine)再到本世纪基于神经网络的深度学习(Deep Learning),大致契合了从既定规则向统计回归再向机器自动化的跃迁轨迹,这背后是符号主义和连接主义从正面冲突走向对立统一的艰苦历程。当下机器学习模型“生成式学习”和“判别式学习”的两种基本架构,正对应着连接主义和符号主义的不同思维模式;前者通过对自然人思维和感官的“仿生”映射出具有指向性的标签化结果,后者则在生成对抗网络的支持下反复“左右互搏”,不断刺激生成器和判别器拟合出全新结果。 在求解指标的运算过程中,机器学习模型并非将既存一般性规范局限到特定指标,而是在给定范围的区间内,创造出具有一般性规范特征的全新指标。在这个意义上,机器学习模型的独特价值在于实现自然人力所不逮的“温故而知新”——在看似毫无关联的海量数据和文本中,挖掘出具有重大意义的内在规律,以人机共同作业的方式来构筑成文法体制下逻辑法学式的推理和演绎,并在此基础上适度创新。由此可见,较之于“判别式学习”构架,“生成式学习”构架不仅能在既有资源下穷尽一切指标搭配组合,还能通过“眼光往返流转”的过程真正实现“知识创造”,更能够满足公共卫生领域的算法治理所需。 机器学习模型进行类似于“法律续造”的规范性风险指标求解,模拟的其实是法诠释学上从特殊性事务到一般性事务的推论过程。所有被求解出的指标,其共通的价值理由不仅适用于拟被纳入评价体系的所有医疗保健机构,反之,也同样适用于类似的情境或具有相近要件构成的风险评估体系中。就此而论,机器学习模型的求解过程具有“目的论扩张”的特性,反过来也必然受到“目的性考量”的拘束:人工智能技术应当致力于推进,而非借助技术优势推翻,长期达成的、普遍承认的价值思考方式,更不能在代码程序中“夹带私货”。就像行政官员必须以“社会中具有支配力的法伦理”为其行为标准一样,人工智能介入公共卫生领域的风险评估,首先应该尊重传统评审机制所保留的“共同意识”,即哈特曼所称的“客观精神”;机器学习模型进一步的评估行为以及规范续造,在很大界限内,必须以先决的价值规范为基准。齐佩利乌斯指出:“一致的价值规范是认识正义的基础。”这将要求机器学习模型在“生成式学习”的操作层面,采用大致类似的自动化处理流程,确保对实现规范所定条件的数据和文本,以及依照对这些数据和文本进行解释取得的概念界定,给予具备横向可比性且前后啮合的处理方式。在上述认知的基础上,算法治理的问题就又转化为,指导机器学习模型运作的算法应当如何选择? (三)合规导向的算法构建思路 考虑到算法治理的正当性源于能够更好地促进风险评估先行监管实践,而公共卫生领域风险评估的规整意向、计划及其内含目的拘束已经为机器学习模型的“法律续造”划定了边界,各类风险指标的求解和生成,务必要回归医院分级评审的“初心”,以科学性、规范性和中立性的彼此调和为其“实践理性”;法律和算法之间的互动从中可以窥见一斑。从基于既定规则的等级评审到基于统计回归的专家排序,再到基于机器学习算法治理,风险指标的选取由自然人向自动化机器过渡,但所有的风险指标“依其位阶衡量轻重”的评估逻辑,始终没有发生改变。有鉴于此,用于缩小增量排序的希尔排序算法,或能有效提升风险指标加权排序的效率,筛选出能更精确映射正常价值秩序的指标组合。 1、希尔排序算法 希尔排序算法的基本思想是:假设待排序的指标序列有多个指标,根据拟构建的风险排序模型的复杂程度,取一个整数n作为间隔,将全部指标分为n个子序列。所有距离为n的指标将被归于同一个子序列,在每个子序列中分别进行直接插入排序。随着大数据的增长,监管部门可以通过缩小间隔n的方式,不断重复子序列的划分和排序过程,以求得“颗粒度更细”的风险排序方式。希尔排序算法的优点在于,可以根据可用数据的多少,灵活控制间隔差值且不会影响排序速度。n的值越大,风险指标的子序列分类越少,模型具有更高的稳定性;n的值越小,风险指标的子序列分类越多,模型具有更强的风险预测能力。不过,依照此算法构建的模型可解释性极低:对希尔排序算法的时间复杂度分析非常困难,只在极少的情况下,专业人士可以从运算结果反向推算排序码的比较次数和元素的移动情况。除此之外,想要弄明白排序码比较次数和元素移动情况与增量选择之间的线性关系,并给出完整的数学分析,基本不可能。 缺乏可解释性是公共治理领域人工智能应用的大忌,究其根源,我们处在一个公众问责空前加强的年代,保障公众“知情权、参与权、表达权、监督权”的施政理念是推进社会主义民主法制建设重中之重。任何新技术的部署都必然被置于传媒与社会持续性互动的场域之中,算法可解释性既是世界各国人工智能法律法规的核心要旨,也是机器学习时代“对抗数据个体的主体性和自治性沦陷和丧失的内在之善”。 无论是基于统计回归的专家排序,还是基于既定规则的等级评审,其背后的“指标之法”早已被拟规整、与之相关的自然或社会关系所预先限定。作为行业“内法”,医院评审的各项隐性或显性指标,是医疗从业者需要去遵守和维护的柔性指引(例如,事故率、就诊病人综合满意度)、是同行业发展息息相关的硬性要求(例如,卫生技术人员学位数、重症医学科床位数)、是约束医疗机构健康发展的良性规定(例如,行风建设、平均住院日),简言之,是以构成性规定作为产生特定行为方式的前提条件的法律规则,是规范而非随意的陈述。想要通过规范来实现准确风险评估的医疗监管部门,必然将受到规整的企图、合目的性考量的影响,最终又将以评价为基础。因此,要正确选取评审指标就必须充分挖掘各项指标所潜藏的评价及该评价的作用范围。进而,在医院评审中,样本数据拟归向的规则或规范本身须经解释,以确定该指标就该数据的精确意义为何。在这样的可解释性要求下,用于公共卫生领域的风险评估算法必然将从难以解释的排序路径向易于解释的聚类或分类路径转换。 2、聚类算法 英国监理质量委员会并未公布其智能评级系统的元算法,但是根据描述,可能是最容易操作的K均值聚类算法,因为只有这类算法才能为监理质量委员会的风险评估结果提供合乎情理的解释,确保智能评级系统符合英国政府推行的《数据伦理框架》。K均值聚类算法的目的是最小化群集惯性因子,它利用机器学习模型识别出大数据中潜在的结构或模式,使相同聚类或组别的元素彼此之间比来自不同聚类或组别的元素更相似,籍此来凸显具有更高响应度的风险指标。在商业上,K均值聚类算法常用于消费者行为模式的识辨,而患者亦是医疗服务中的消费者。顺着这个思路,监管部门可以以医疗数据库为基础,找到不同种类疾病的最佳质心,从而决定患者样本的簇类别,利用平方欧几里德距离将病患数据分配给各个类别,并多次重复初始化过程以解决非凸函数难以收敛到局部最优的问题。然而,K均值聚类算法对非球形群体的识别效果欠佳,难以适用于我国公共卫生领域的算法治理。我国医疗数据库中现有的各类可量化指标主要来自于各医院的填报,监管部门虽有审核权限却不具备一一现场核实的能力,使得虚报和瞒报等机会主义行为层出不穷。打个不恰当的比喻,各地粮仓历年向中央汇报都是库存充足、米面无忧,缘何一开展大清查、巡视组入驻,就频频“火烧连营”呢? 3、C4.5分类算法 相较于聚类算法,分类算法可以更好地解决群体识别问题,且不以算法可解释性的牺牲为代价。应用最广泛的分类算法是C4.5算法,由ID3算法拓展而来。C4.5算法可以用于将具有多维特征的多个指标分配进不同类别中,以“投影”的方式,将多样属性指标类别标签化。可以将分类的过程视为一颗“决策树”,每次通过选择不同的属性,来进行分叉。例如,在医院风险评估中,可以分别建立一个反映各类风险指标的属性集A={依法执业,医疗安全,诚信执业,行风建设,重大事件,指令性任务,突发公共卫生事件,病理学指标},一个类别集合L={提高风险评级,降低风险评级,维持评级,勒令整改},属性和类别集合划分越细,模型的复杂程度越高。C4.5算法的第一步是分别计算每个属性和每种类别的信息熵,即各种属性和类别各自可能出现的不确定性之和。信息熵的值越大,表明该属性或类别的样本越不纯,将数据厘清所需的信息量就越大。第二步,计算信息增益确定特征指标。信息增益为类别信息熵和属性信息熵的差值,反映了信息不确定性减少的程度。一个属性信息增益越大,说明利用该属性进行样本划分能更好降低不确定性。在这一步,算法模型对医院风险评估中的可用指标,进行了自己的判断和抉择,部分指标被剔除或维持“有意义的沉默”状态。第三步,计算属性的分裂信息度量,即将各属性“上树”,开始分叉的过程。根据数据量的大小和数据搜集周期的不同,不同的属性有着不同的数量和尺寸,这些信息是属性的内在信息。信息增益和内在信息的比值,为信息增益率,反映了属性的重要性随内在信息的增大而减少。算法模型将筛选出信息增益率最高的指标作为“叶子节点”,利用不“纯”的节点进行继续分裂,就像构建一棵树那样,完成对各个风险指标的吸收与积累,进而兑现合理归类的承诺。 从上述拆解来看,算法可解释性要求——或其他任何法律意义上的合规限制,已经完全可以深入机器学习模型和算法的构造层面而非仅仅停留于以概括形式固定法规范的一般性规则层面。算法治理的构建路径不一而足,但其本质是经由多个彼此之间相互“卷积”的机器学习模型——其函数联结和指标生成满足起码的、可被检验的一致性和规范性要求——所构成的治理体系。需要关注的是,算法治理在理论上的可以实现,并不等同于现实意义上的有效实现。“操作方式”需与“法律保障”相辅相成,才能逐级克服算法治理的潜在缺陷,最大化风险评估先行治理路径可能带来的社会效益。 从价值秩序到法律保障: 公共卫生领域的多元共治体系 和一般的法条并无二致,医院评审的各项规则首先是陈述性的,因为它们指出了受评医院在理想状态下之应然;同时,这些规则又是规范性的,直接作出了规定、给予或拒否的表示。相较于规范性功能而言,规则的陈述性功能居于次要地位。机器学习模型所依赖的算法,无论是K均值聚类算法、希尔排序还是C4.5算法,本身不具备陈述性,也不具备规范性,但它们一旦结构性地嵌入社会权力运行系统,将以“持续控制形式”干预、引导和改造日常社会互动,可见“算法即法律”之洞见所言不虚。法律关系的根本性重塑呼吁“构建一体融合的法律体系,探索新型的代码规制方式,塑造高度自主的精细化治理秩序”,这也是公共卫生领域算法治理所必须的基本法律保障。概而论之,利用算法实现风险评估先行的监管路径,所面临的法律挑战不仅仅是“更复杂的技术”以及“更多的数据”对个人权利的侵蚀乃至剥夺,更是在监管职能和数据归属日趋分散的背景下,如何构建适当的法律制度来避免算法外部性的弥散和不合理转嫁。 (一)宏观政策法规保障行业联动 理想的情况下,准确的医院分级评审结果或具有多样化的用途。对于参评的各医疗保健机构而言,它是可以用于改良医疗服务、提升应急能力的实时综合评价;对于中央监管部门和地方监管部门而言,它是卫生执法监督体系中监管资源调配的辅助工具,也是突发公共卫生事件中掌握疫情动态、明确防控重点的决策依据;当然,对于广大病患而言,它也可以是入院就诊的声誉参考。无论被重点作为哪一种用途,医疗保健机构的风险评估结果都具有消费的不排他性、效用的不可分割性以及受益的不可阻止性,即在给定的生产水平下,作为信息使用者的医疗机构、监管部门和患者额外获取或使用此类信息的边际成本为零,任何人对它的使用都不会减少或排斥其他人的使用。 众所周知,公共物品只能由政府来提供,因为消费者一旦认识到自己的机会成本为零,他就会尽可能减少换取消费公共物品权利的对价,使得市场机制分配给公共物品生产的资源处于帕累托最优之下。当消费者的给付不足以弥补公共物品的生产成本时,将诱发公共物品提供者变相创收的道德窘境,势必会削弱公共物品的品质。政府主导医院分级评审的合法性根源正源于此,而且,公共物品的生产成本越高昂,就越需要有公信力的政府发挥效用。基于既定规则的等级评审和基于统计回归的专家排序尚可以交由第三方机构以立项获取财政拨款的形式完成,基于机器学习的算法治理则只能由政府部门牵头,推动不同的公共管理部门同私营部门紧密合作,才有可能取得成功。公共卫生领域算法治理的实现,必须以规模足够庞大的医疗数据库以及分布相对均匀的病患样本作为基础,必须依靠完整的、实时的、多渠道的数据信息链才能获得可靠的风险评估结果。尤其是,医疗服务中的诸多细枝末节也必须要包括在内,例如一次完整的就诊过程中各个时间节点的评价与互动、历次预防保健工作中已经司空见惯的临床流行病学调查结果等,否则机器学习模型的潜力将无法完全发挥。但是,符合国家统一标准、超大型数据库的建立以及在相当长一段时间内合格患者的样本采集,定然是一项任重而道远的社会工程,需要强有力的政策、法律和国家财政支持。 作为化危机为契机的重要手段,算法治理必然带来政府职能的结构性转变。虽说“政府主导”,但国务院《决定》等文件中的“简政放权”精神依然应当得以贯彻和落实——在基于既定规则的等级评审中是“政府主导评审”,在基于机器学习的算法治理中就应当转变为“政府主导扶持”。 其一,算法治理的兴起必然催生新型的监管分析师职业。机器学习模型虽然具有指数级优于自然人的算力,但由于大数据的结构化处理尚不能自动完成,监管部门的人力资源上限将成为阻碍机器学习模型发挥实力的瓶颈。英国监理质量委员会智能评级系统常因处理数据旷日持久而备受非议,如果不能依照即时数据“以变应变”,算法治理充其量只能算作用计算机化的手段模拟基于统计回归的专家排序而已;与其无休止地规定数据“真实性”,不如为数据的“及时性”提供法律保障。 其二,算法治理需要大范围、多部门、众行业的数据共享,以便更完整地覆盖同公共卫生相关的活动、业务和流程。新冠病毒的高变异性、强传染性和深度潜伏性使其超越了一般健康事件的范畴上升至“公共道德事件”,以行政手段带来的“社会共律”是对社会个体普遍自律不足的必要补充,健康码作为算法治理一个可能的切入点具有了合法性根据。我国战“疫”的阶段性成功,正是因为群防群治、联防联控下沉到社区,对潜在危险人群进行了“饱和式追踪”。扩大数据挖掘范围、拓展算法应用场景,将有助于达成精确的“网格化管理”、提升疫情管控能力、消除密闭空间内人与人之间的相互不信任。 需要指出的是,“政府主导、各数据所有者积极配合”的治理结构,意味着传统权力专属原则和正当程序原则极有可能因“权力外包”被架空。掌握数据的企业和平台寡头横亘在政府与公众之间,形成了公权力、私权力和私权利的多方博弈格局,外溢出来的准公权力必须予以规制,否则将带来权力私有化和商品化的异化风险。政府部门应当限定与之合作的企业和平台的数据采集类型、渠道和使用方式,制定数据共享责任清单,并对相对敏感的隐私信息采取加密储存、限制传输、访问控制等安全措施。受政府委托进行数据加工、处理和分析的企业和平台,必须要严格遵守相关法律和分工,不得违反协议约定私自备份、二次利用或将医疗数据提供给第三方。数据分级保护的思路还预示着对域外数据规制法律长臂管辖权的适度阻断,应以国家立法的方式合理构建数据所有人(公众)、数据采集方(企业或平台)与数据处理使用方(政府部门)之间的信息权益体系,完善科技支撑的社会治理体系。 (二)中观价值谱系重构评审规范 从规则形成的角度来看,所有公共卫生领域的风险评估方式,无论是基于既定规则的等级评审、还是基于统计回归的专家排序,甚至是基于机器学习的算法治理,均是人们在繁复又未必令人满意的价值导向的思考之上,生发出价值判断形成的契机,又通过监管部门的采纳和批复,成为具有指导意义的风险评估方式。在实现风险评估先行的监管路径的首要价值取向之外,监管部门也同时追寻并维护着现行有效的价值规范。这些价值规范彼此之间有着与时俱进的阶层秩序,多数时候完全取决于政策制定者的偏好,但它们决定了机器学习模型的规范续造边界,是算法程序设计和运行必须遵守的元规则。将现行主流评价体系进行梳理和整合,可以发现公共卫生领域世界通行的基本价值结构(如下图所示)。 上述价值谱系体现出了各国在公共卫生领域为实现风险评估先行的监管路径所做的各项努力。虽然在不同时期各有侧重,但这些价值规范体现出的对指标合理性、目的明确性、评价中立性、审查科学性、标准一惯性以及将临床和预防结合的追求,反映了各国监管部门基于公共卫生领域内在秩序不断将外部实践所得真理融合成一致价值规范的孜孜不倦的努力。近年来,由于基于统计回归的专家排序的盛行,公共卫生领域的多数高阶价值,已经完成了相关数据的稳定搜集和结构化改造。对于部分算法无法直接读取和使用的非结构化信息,例如过于主观的患者评价、标准不一的并发症预防规范、难以言传的康复治疗过程等,机器学习模型也可以通过对原始数据和文本的深度挖掘,提取关键特征,通过分布式处理逐渐抽象出甚至将其重构为结构化数据。无论采取哪种算法,卷积神经网络能够以组合底层指标、提炼高层指标的方式计算风险指标的权重差值,利用多层级的结构叠列与前后输入的逐步拆解,完成各价值规范之间的阶层排序。就此而论,卷积神经网络确非只是“指数级地将既定规则复杂化”,而是在价值元规则的基础之上周而复始地构建出决定价值阶层秩序的衍生规则。 亟待解决的问题是,当下对算法可解释性的硬性要求,虽使得机器模型的求解过程看似可审查,却不足以确保算法将重要的自然人价值规范一以贯之;相关的法律规定只是迫使监管部门加大寻求正当化算法治理的理由而已。在技术黑箱的面纱之下,多少算法治理的尝试并未真正排除监管者和立法者的肆意妄为——在美国,用于家暴防范的儿童保护系统不仅没有大幅降低虐童事件的发生概率,还造成了上万正常父母同其子女的被迫分离;在法国,银行间通用的客户资信考察系统,曾一度拒绝为单亲家庭成员提供住房贷款——对算法治理的解释是事后添加的,而解释说理的方式完全取决于政治目标。即便监管者和立法者的意志被排除在外,谁能保证编码算法的程序员不将自我价值负载强行写入代码之中呢?“法官对于法律用语不可附加任何意义,毋宁须以受法律及立法者拘束的方式,来发现法律的语义内容”,而未经过系统法律训练的程序员,却只能依照自己对价值元规则的见解以及对立法者意志的揣测,完成机器学习的建模,致使计算机语言不仅不能精确地转译法律规范,还会因为理解偏差使之与正常涵义相去甚远。例如,将法律规则编入美国科罗拉多州公共福利系统时,程序员将“无家可归”错误解读为“行乞为生”,使得本应获得政府救济的流浪汉们被算法系统拒之门外。面对这种语言理解和事实认定的巨大差异,以过失和疏忽为构成要件的一般侵权责任以及以信义义务为核心的事后审查机制都于事无补。不克为此,我们能否通过更精确的语言来减少转译过程的偏差和耗散呢?透过解释确实可以将模糊的概念精确化,但逻辑上的连锁推论,未必就能更好地适用于意义涵摄,因为中间步骤越多,就越不能终局地定义概念。在价值陈述方面要做到这一点更是难上加难,正如考夫曼指出的那样:“语言的极端精确常以内容意义的极端空洞作为代价”。 对算法可解释性的法律规定进行补强的解决方案之一,是以成文法的方式,强行要求在机器学习模型环节引入同行评议,由外部同行对模型和算法构建进行审查。《英国政府数据伦理框架》已将法定同行评议视为算法治理的“质量保障”,但从未给出切实可行操作方案。技术优势方常以专利保护为由,对自己的“算法秘方”三缄其口,但受控文本处理方式下的“适当开源”,在技术上完全可以实现。公共治理学者在“后常态科学”的语境下提出了“同行社区”的概念,以“利益相关者的对话参与”取代过去“个体偏好简单叠加”的治理范式。但将机器学习模型的外部审查权限拓展至同算法治理休戚相关的所有人,似乎有些矫枉过正,甚至会对技术开发方造成反向激励。无论机器学习模型多么强大,自然人需固守的底线是贯彻“独立并超越机器判断的、客观真实反映基本价值”的标准。在公共卫生领域,法定同行评议的重点审查方向,是本节图表中的各项基础价值在算法代码中是否得以表达以及不同价值的权重和规则秩序是否符合当下的实际需求。具体而言,同行评议应对算法求得的风险指标进行有目的的审查,一是“向上”回溯机器学习模型的求解路径是否具体化了特定的社会价值理念,二是“向下”检视各风险指标的加权与赋值是否与实证的具体结论大致相符。除了应具备规范性、满足一定程度的社会实效性之外,机器模型试图构建的风险评估先行的算法监管路径,还应当反映出在伦理方面最低程度的正当化努力。 (三)微观法律规则消弭算法歧视 机器学习模型不以实物或现象所有的构成部分及其组合或排列而成的丰盈具象来把握自然人通过感官和思维来认识的客体,易言之,不是将其作为唯一无二的整体来进行理解和对待,而是透过对数据和文本的深度挖掘以掌握其中个别特征或要素,并借助这些个别特征或要素去理解其他的特征或要素,以及他们之间可能存在的线性关联。这种“升格推演”的求解路径决定了,相较于基于既定规则的等级评审和基于统计回归的专家排序,基于机器学习的算法治理在受评医院的歧视方面,有过之而无不及:法学家们称为算法的“自反性现象”或“诺米克博弈”。例如,机器学习模型根据人群聚集密度和高危人员流动轨迹推算出某一区域可能存在大量的无症状感染者,从而触发更高频度的核酸检测;更多的检测必然“揪出”更多的感染者,这将反向刺激针对该区域施行更高强度的算法监管,“越关注越感染、越忽视越‘安全’”的自反性悖论由此产生。由此引出的重要问题是,在医疗保健机构的风险评估方面,如何才能跳出传统评价体系导致受评医院“强者恒强、弱者恒弱”的自反性悖论呢?规范法学给我们的教义是,根据拟衡量的要求或标准所具有的准则性和拘束性探求规则的规范性效力——逻辑上的统一来自于系统化,而系统化的前提是对知识进行联结化处理。具体到医疗数据的结构化处理过程中,监管部门应当出台相关的操作规范指引,要求搜集、处理和分析数据的企业或平台通过指数调整等界值方式确保:(1)民营医院、私人医疗卫生机构和公立医院在管理方法、评价标准和评审周期方面具有可比性;(2)各医疗服务机构在目标使命、科室设置、人员配比、行风建设、病患负担、资源分配方面具有可比性;(3)大型医疗设备在引进目的、使用频率、换代频率、维护成本、工作负荷、闲置周期等方面具有可比性;(4)专业技术人员在职称评审难度、授予机构差异以及发文硬性指标方面具有可比性;(5)同种类型的病症在感染比例、处理方式、收费方式、复诊标准和痊愈判定方面具有可比性;(6)患者的评价和判断在有效性、可靠性、一致性和公正性方面具有可比性。 总之,在权益保护方面,微观层面的操作规则比国家层面的政策和中观层面的法律更加有效,因为基层公共部门能更贴近事物的本质实现“适当地规整”,同时还能站在相关人的角度兼顾各项规则可能引发的信赖利益。简政放权下沉到基层的自由裁量权,或将有助于一线公务员对国家宏观政策不折不扣地落实以及同中观价值谱系严丝合缝地衔接,这着实意味深远。 结语 疫情并未远去。面对严峻复杂的世界政治经济形势,统筹推进疫情防控和经济发展,将更有赖于风险评估先行的监管路径。技术飞跃与治理提升之间的关联通常被人们假定,也早已被政策捕捉,却通常缺乏学理上的解释和要素上的证成。算法治理之实现,方法论的纯净并非不可或缺,为求中立步入规则机械化的歧途必不可取。监管精细化的前提是治理平台化、价值秩序化和正义场景化,纯粹理性和实践理性的平衡有赖于制度化的法律安排,避免公共决策走向“纯粹恣意的个人主张”和“空洞无情的公式理性”两个极端。公共卫生领域如此,其他公共治理领域也概莫能外。 法律的终极原因是社会福利,技术亦然。后疫情时代,公共卫生领域算法治理的“成与不成”,取决于三重假设的交互:其一,程式设计者能在多大程度上将妥当的考量结构性转化为机器模型可执行的问题和任务,并有足够的数据样本和试错余地作为支撑;其二,行业监管部门有多大能力确保算法程序严守价值规范秩序,且辅之以必要的技术人力资源;其三,立法者有多大智慧平衡社会公共利益和个人隐私保护,在不牺牲政策透明度的情况下取得“多数人同意”。良法得到普遍遵从乃法治,技术壁垒或将日益加大算法可解释性的鸿沟,但倘若能将法治思维贯穿于算法治理的各个流程,那便是以看得见的方式实现了以个人健康促进社会健康的最大正义。 涉及文字转载、内容推送事宜 请联系:贾海东 15527926120 本期编辑:侯子璇 | 校对:汪玥 审核老师:李安安 | 袁康